Member-only story
Everything I know about distributed locks

Locking, often, isn’t a good idea, and trying to lock something in a distributed environment may be more dangerous. But sometimes, we need to keep this risk and try to use a distributed lock for two main reasons:
- Efficiency: a lock can save our software from performing unuseful work more times than it is really needed, like triggering a timer twice.
- Correctness: a lock can prevent the concurrent processes of the same data, avoiding data corruption, data loss, inconsistency and so on.
We have two kinds of locks:
- Optimistic: instead of blocking something potentially dangerous happens, we continue anyway, in the hope that everything will be ok.
- Pessimistic: block access to the resource before operating on it, and we release the lock at the end.
To use optimistic lock we usually use a version field on the database record we have to handle, and when we update it we check if the data we read has the same version of the data we are writing.

Database access libraries, like Hibernate, usually provide facilities to use an optimistic lock.
The pessimistic lock instead will rely on an external system that will hold the lock for our microservices.
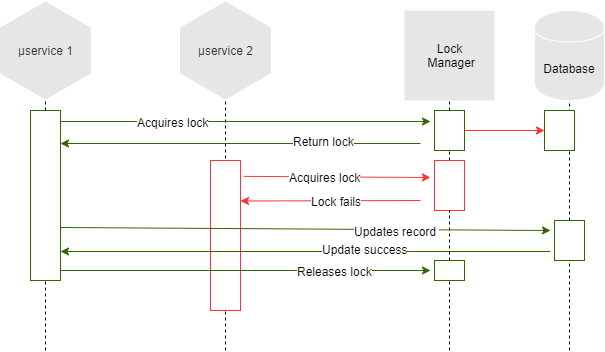
As for optimistic lock, database access libraries, like Hibernate usually provide facilities, but in a distributed scenario we would use more specific solutions that use to implement more complex algorithms like:
- Redis, using libraries that implements lock algorithm like ShedLock, and Redisson. The first one provides lock implementation using also other systems like MongoDB, DynamoDB, and more.
- Zookeeper, provides some recipes about locking.
- Hazelcast, offers a lock system based on his CP subsystem.
Implementing a pessimistic lock we have a big issue, what happened if the lock owner…
